Vision with LLM
ViT (Vision Transformer)
ViT (Vision Transformer) 是 Google 在 ICLR 2021 提出的里程碑式工作。它把 Transformer 架构直接搬到图像域,在大规模预训练上打破了 CNN 的统治。CLIP、LLaVA、Stable Diffusion 等多模态模型都以 ViT 作为视觉骨干,因此面试常考。
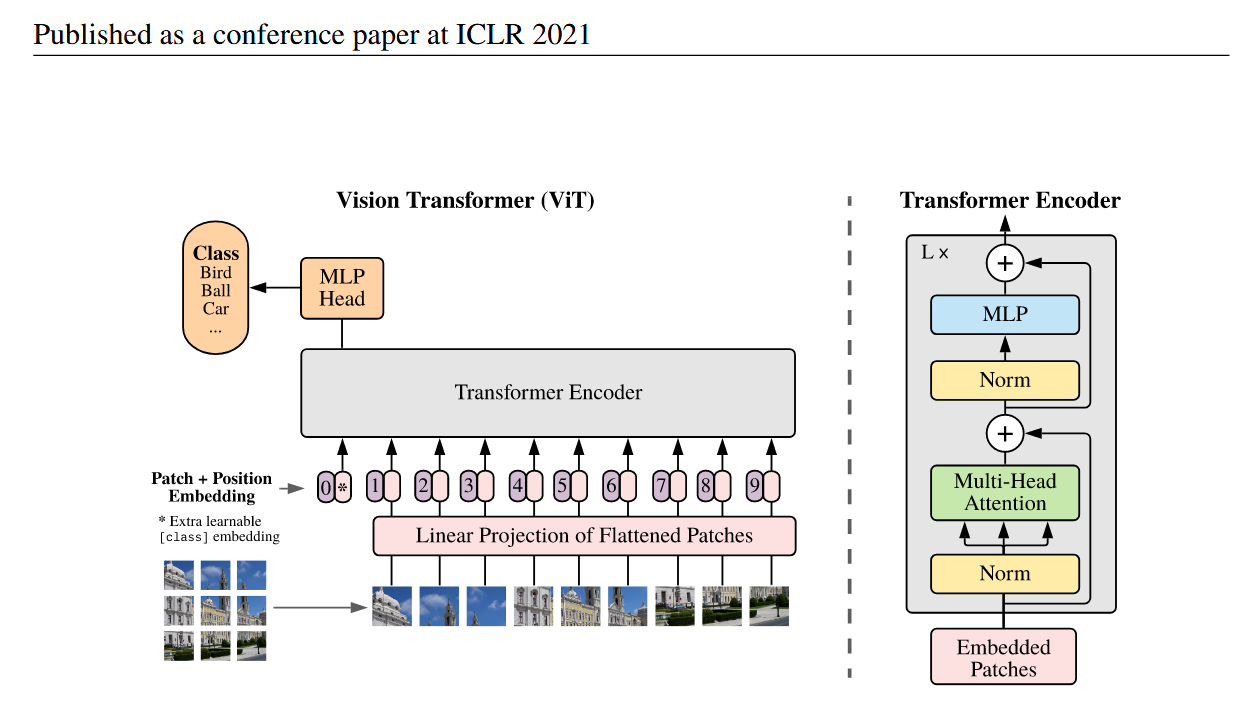
一、核心思想:An Image is Worth 16×16 Words
- 把图片均匀切成 Patch,把每个 Patch 当成一个 Token;整张图就对应一个 Token 序列。
- 不再依赖卷积的局部归纳偏置和平移不变性,第一层自注意力就拥有全局视野。
- 视觉和语言共享 Transformer 结构,图文特征更容易对齐。
二、架构流程(Pipeline)
假设输入图像尺寸为 H × W × C(如
224 × 224 × 3),Patch Size P = 16,Embedding
维度 D = 768。
- Patch Partition
将图像切成N = (H × W) / P² = (224 × 224) / (16 × 16) = 14 × 14 = 196个 Patch,每个 Patch 的形状为P × P × C。 - Linear Projection / Patch Embedding
展平每个 Patch,并通过线性层映射到D维。工程中常用Conv2d(kernel_size=stride=P)直接完成切块 + 映射。 - Positional Embedding
Transformer 对序列无序,需要向 Patch Embedding 中加可学习的 1D 位置编码,保留 Patch 的空间位置。 - Class Token
在序列最前插入可学习的[CLS]token,序列长度从N变为N+1。分类时读取[CLS]的输出向量。 - Transformer Encoder
堆叠L层 Pre-Norm Transformer:LN → MSA → LN → MLP(FFN),层间带残差连接。 - MLP Head
最后再接一个LN + Linear,输出分类 logits。

三、ViT vs. CNN(面试高频题)
| 维度 | CNN (ResNet) | ViT (Transformer) |
|---|---|---|
| 归纳偏置 | 强:先验地假设局部性与平移不变性 | 弱:没有结构先验,全靠数据学习 |
| 数据需求 | 在小数据集上易训练,表现稳 | 需要海量数据(JFT-300M 等),ImageNet-1K 上训练更难 |
| 感受野 | 局部 → 随层数加深逐步全局 | 天然全局,第一层即可关联所有 Patch |
| 计算复杂度 | O(H × W),与图像分辨率线性 |
O(N²),与 Patch 数平方成正比,分辨率高时显存压力大 |
| 多模态适配 | 特征空间与文本差距大,难对齐 | 与 LLM 架构一致,便于图文对齐(CLIP) |
四、关键技术细节
- 位置编码外推:训练时
224²,测试时384²会导致 Patch 数变化。常对预训练的 2D 位置编码做双三次插值(Bicubic Interpolation)以适配新长度。
- 小数据表现差:缺乏卷积的归纳偏置,只能靠大量数据学习“邻近像素相关”这类先验,因此小数据上易过拟合。
- 自注意力复杂度:
Complexity = O(N² · D),N为 Token 数。在高分辨率下成本过高,于是衍生出 Swin、Window Attention 等改进来降复杂度。
五、常见变体(SOTA 储备)
- Swin Transformer:窗口注意力 +
移位窗口,使复杂度近似线性
O(N),适合检测和分割。
- MAE (Masked Autoencoders):ViT
自监督预训练范式,随机 Mask 75%
Patch,让模型重建像素,预训练表现突出。
- DeiT (Data-efficient Image Transformers):引入 Distillation Token,让 ViT 在 ImageNet-1K 这类中等规模数据上也能高效训练。
六、手撕代码:Patch Embedding(PyTorch)
1 | import torch |
七、总结与代表模型
- ViT 是多模态大模型的“视觉骨干”,掌握 Input/Output 维度、Patching
机制与 CNN 的区别是面试必备。
- LLaVA:CLIP-ViT-L/14。
- Qwen-VL:ViT-bigG。
- Stable Diffusion:CLIP-ViT-L/14。
CLIP (Contrastive Language-Image Pre-training)
CLIP 是 OpenAI 于 2021 年提出的双塔多模态模型,被称为“图文对齐的基石”。在多模态岗位面试中,它的核心思想、损失函数与工程细节几乎必问。
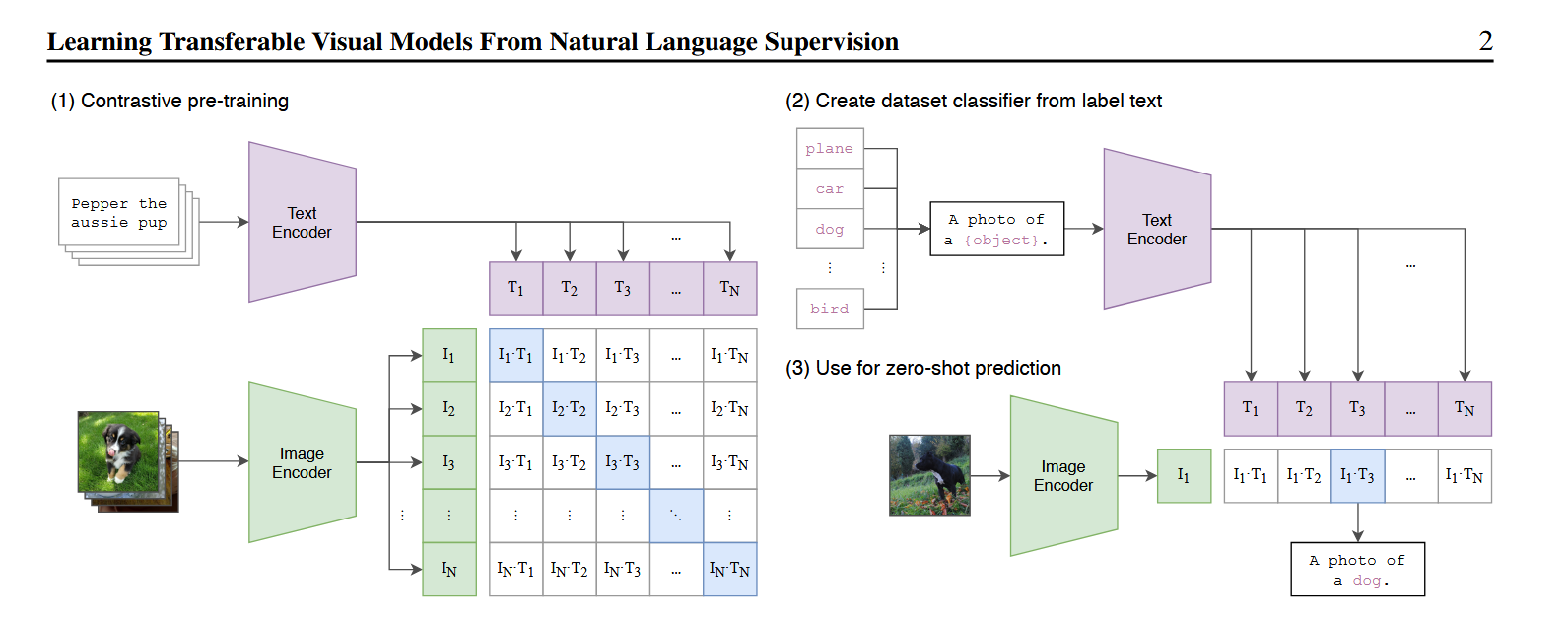
一、核心思想
- 使用图像编码器和文本编码器分别提取特征,再映射到统一语义空间。
- 通过对比学习(Contrastive Learning)拉近正样本距离、推远负样本距离,从而实现 Zero-shot 分类。
- 面试金句:CLIP 打通视觉与语言的语义壁垒,让模型“看图懂语义”。
二、架构细节
- Image
Encoder(视觉塔):ResNet-50、ViT-B/16、ViT-L/14 等结构,输出
D维视觉向量。 - Text Encoder(文本塔):Transformer 结构,输入加入
[SOS]、[EOS],取[EOS]位置作为句子表示。 - Projection Head(映射层):线性层映射至同一维度并 L2 归一化,无 Cross-Attention,推理高效。
三、训练目标:对比学习
数据规模:WIT-400M(4 亿图文对),弱监督规模决定上限。
相似度矩阵:对 batch 中
N对样本分别得到{v_i^I}和{v_j^T},计算下式(归一化后即余弦相似度):\[ S_{ij} = v_i^{I} \cdot v_j^{T} \]
InfoNCE / 对称 Cross Entropy:
- 对角线
(i, i)为正样本,其余为负样本。 - 行维度做 Softmax(Image→Text),列维度做 Softmax(Text→Image),两者平均。
- 引入可学习温度
τ控制分布尖锐度,通常约束τ ≥ 0.01避免梯度爆炸。
- 对角线
1 | # image_encoder: ResNet / ViT |
四、Zero-shot 推理
- Prompt Engineering:将标签写成模板句子
A photo of a {label}.。 - 使用文本塔编码所有 Prompt,缓存文本特征。
- 图片通过视觉塔得到特征,与所有文本特征计算余弦相似度,得分最高者即预测。
- 多模板取平均可显著提升 Zero-shot 表现。
五、面试常问问题
- 为什么 Batch Size 极大? 对比学习依赖负样本,Batch 越大,负样本越多,特征越鲁棒;CLIP 训练 Batch 可达 32K。
- 温度
τ的作用? 调节 Softmax 尖锐度,CLIP 中为可学习标量,常在 log 域裁剪保障下界。 - 有哪些局限? 不擅长计数/空间关系/OCR,输入分辨率 224×224 对小目标不敏感。
- 相比 ImageNet 预训练优势? 数据量大、语言监督更丰富、对分布偏移更鲁棒。
- 如何拓展到检测/分割? GLIP、Grounding DINO、RegionCLIP 通过区域对齐文本;结合 SAM 可做文本分割。
六、应用与地位
- Stable Diffusion:使用 CLIP Text Encoder 解析 Prompt。
- LLaVA / Qwen-VL:采用 CLIP ViT-L/14 作为视觉骨干再接 LLM。
- CLIP + ViT 基本覆盖现阶段多模态视觉前端 80% 的面试考点。