ResNet and Transformer
一份把 CNN 与 Transformer 串起来的快速笔记,记录关键公式、训练直觉与二者之间的联系。
1. 深度网络训练循环
- 正向传播:输入沿着网络逐层计算得到输出。
- 计算损失:把输出与标签送入损失函数,得到标量损失。
- 反向传播:利用链式法则计算各层梯度。
- 参数更新:优化器使用梯度更新权重,循环往复。
2. CNN 基础组件
2.1 卷积层与特征提取
- 卷积核在图像上滑动,通过局部感受野提取空间特征,可并行堆叠多组卷积层。
- 示例:输入为 224×224×3,使用 64 个 7×7 卷积核、步长 2,可得到 112×112×64 的输出;空间分辨率减半、通道数等于卷积核个数。
- 更深的卷积核(通道数更多)可以捕获更复杂的特征模式,输出 tensor 的空间尺寸由步长与 padding 控制。
2.2 ReLU(Rectified Linear Unit)
- 引入非线性,提升模型表征能力。
- 通过截断负值缓解梯度消失,使深层网络更易训练。
2.3 池化层
- 常见的 2×2 最大池化会在每个窗口取最大值,输出 56×56×128 这样的结果(由 112×112×128 池化而来)。
- 作用:降低空间分辨率、聚合局部信息、减少计算与过拟合风险。
2.4 全连接层与 Softmax
- 卷积与池化得到的 feature map 需要展平为向量,再送入全连接层。
- 例:56×56×128 = 401408 维输入,如果映射到 4096 维,需要一个 4096×401408 的权重矩阵和 4096×1 的偏置:
- 对于 10 类分类任务,再接一个 10×4096 的线性层即可得到 logits。
- Softmax 会把 logits 变成概率分布,满足
:
2.5 梯度消失的来源
- Sigmoid/饱和激活:导数最大仅 0.25,在正负饱和区几乎为 0,多次连乘后梯度指数级衰减。
- 权重初始化过小:若
,反向传播会不断乘以 0.01,导致梯度趋近 0;因此需要 Xavier、He 等初始化策略。 - 网络过深:梯度沿 L 层回传需要连续乘以
,只要每项略小于 1 就会快速衰减。 - 缺少跳连接:传统链式结构中,梯度必须层层穿过,无法绕过表现较差的中间层。
3. ResNet 的核心思想
3.1 残差连接公式
- 残差块输出:
。其中 是若干卷积、BN、ReLU 组成的残差分支, 是恒等映射。 - 反向传播:
“+1” 让梯度至少能直接传回前层,避免被多次连乘压缩为 0。
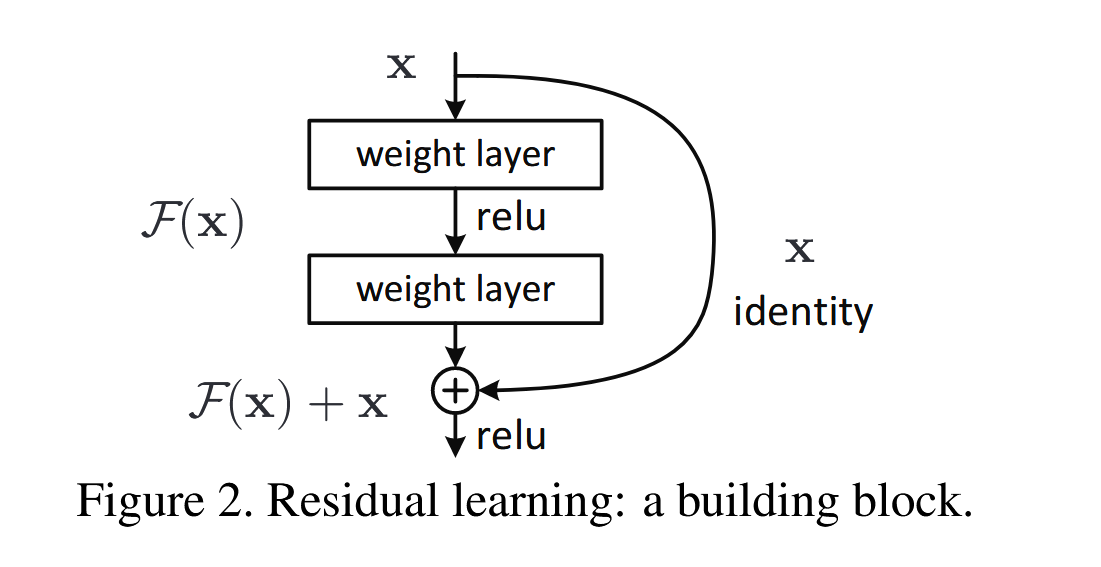
3.2 退化问题与 ResNet 的改进
- 传统深层网络层数增加时,训练误差反而上升(退化现象)。
- 论文中 34 层的 plain 网络在 ImageNet 上 top-1 误差为 28.54%,比 18 层的 27.94% 更差;而引入残差后的 34 层网络可降至 25.03%。
- 原因:若某些层无法进一步提升性能,残差分支可以学到
,整个块退化为 ,深度增加不会破坏已有表示。
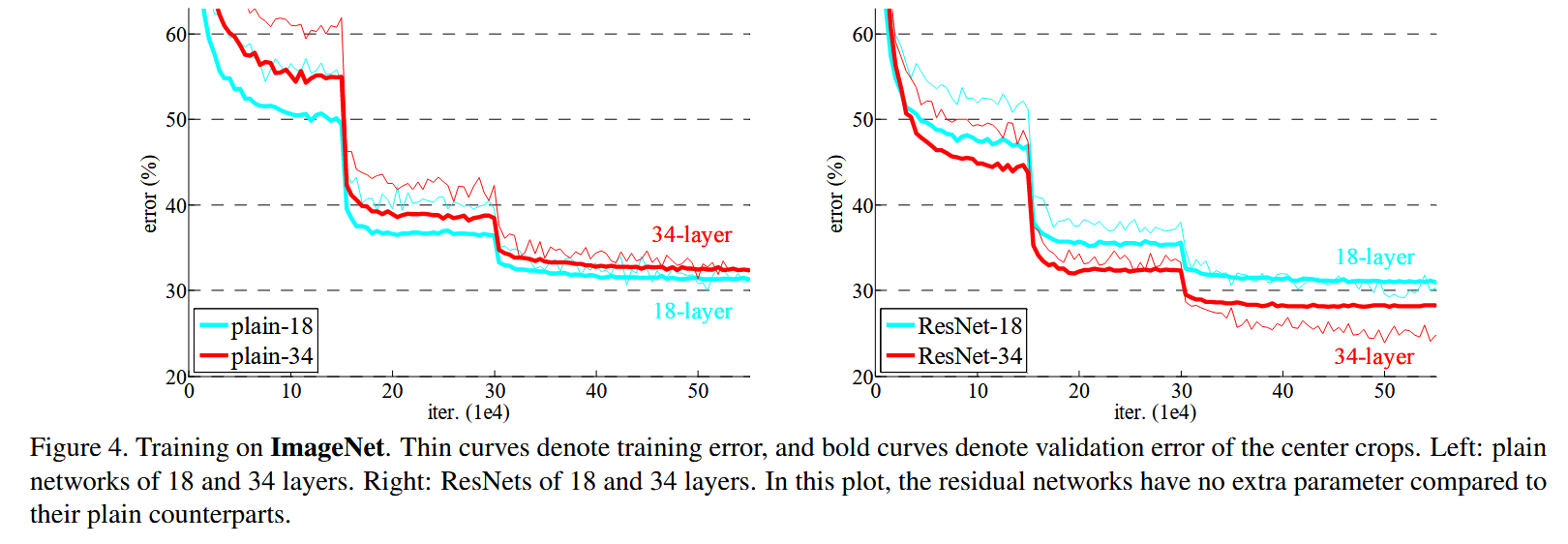
3.3 残差块结构示意
1 | 输入 x |
- 若维度不一致,可用 1×1 卷积或投影矩阵把
调整到同一形状再相加。 - 残差路径允许信息“跳层”,即便中间卷积暂时训练不好,也不会阻碍梯度流动。
3.4 与 Transformer 的联系
- Transformer 将残差思想推广到自注意力与前馈子层:输出统一写作
- 这同样让梯度可以直接穿过自注意力或 FFN 子层,稳定深堆叠结构。
4. Transformer 架构速记
4.1 整体结构
- 经典 Transformer 采用编码器-解码器架构:每层由自注意力 + 前馈网络组成,堆叠多层后可建模长序列关系。
- 解码端还包含编码器-解码器注意力,用于关注编码器输出。
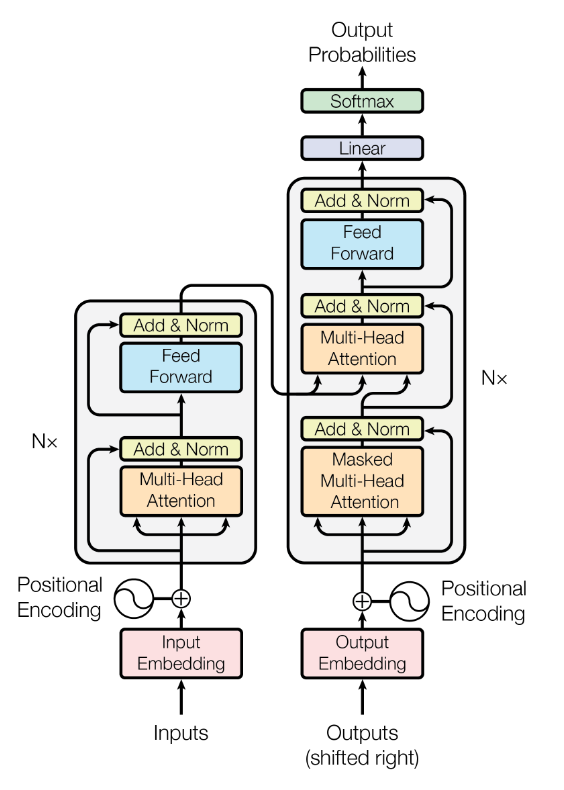
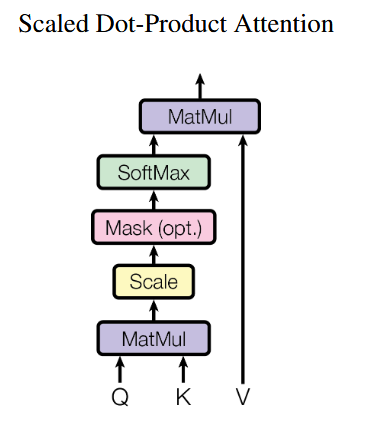
4.2 自注意力(Scaled Dot-Product Attention)
- 输入被映射为查询
、键 、值 ,注意力计算为:
- 点积注意力可利用高效矩阵乘法实现,内存友好。
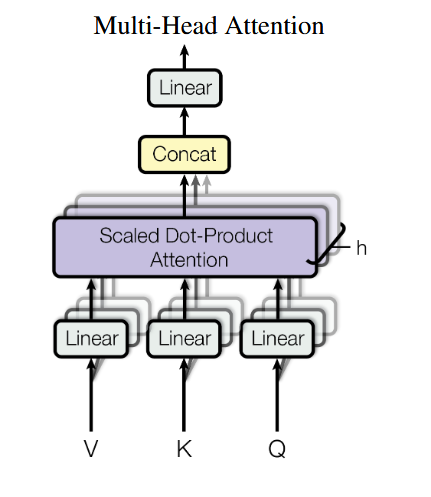
4.3 多头注意力
- 多头机制让模型同时关注不同子空间:
- 每个头的维度较小,使整体计算量与单头注意力相近,却能捕捉多尺度依赖。
4.4 自回归与注意力掩码
- 语言模型满足自回归分解:
- 为保持自回归性质,解码端在计算自注意力时会对未来位置加上
的 mask,使 softmax 仅依赖已生成的 token。
4.5 Position-wise Feed-Forward Network
- 每个位置独立的两层感知机,对所有位置共享权重但不同层的参数互不相同:
- 可视作核大小为 1 的卷积,常用内层维度
。

4.6 Embedding、Softmax 与参数共享
- Token ID 先通过嵌入矩阵映射到
维空间;同一矩阵也可用于输出层(权重共享),解码器 logits 需要乘以 Softmax 才能得到概率分布。 - 为保持数值稳定,输入端嵌入通常再乘上
。
4.7 位置编码(Positional Encoding)
- 纯注意力模型缺乏位置信息,需要额外向量注入顺序。论文采用固定的正弦/余弦编码:
- 每个维度对应不同频率,可通过线性变换刻画相对位置信息,易于泛化到更长的序列,并且无需额外参数。